Installation of OpenCV
I installed OpenCV on a Raspberry Pi.
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install python3-opencv
$ python
>>> import cv2
>>> print(cv2.__version__)

sudo apt install python3-opencv
Installation of TensorFlow Lite
I installed TensorFlow Lite.
$ sudo apt-get update
$ sudo apt-get dist-upgrade
$ git clone https://github.com/EdjeElectronics/TensorFlow-Lite-Object-Detection-on-Android-and-Raspberry-Pi.git
$ mv TensorFlow-Lite-Object-Detection-on-Android-and-Raspberry-Pi tflite1
$ cd tflite1
$ sudo pip3 install virtualenv
$ python3 -m venv tflite1-env
$ source tflite1-env/bin/activate
$ bash get_pi_requirements.sh
Using Google's sample TFLite model
I downloaded and ran Google's sample TFLite model.
$ wget https://storage.googleapis.com/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip
$ unzip coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip -d Sample_TFLite_model
$ python TFLite_detection_video.py --modeldir=Sample_TFLite_model --video=test.mp4
$ python TFLite_detection_video.py --modeldir=Sample_TFLite_model --video=dog.mp4
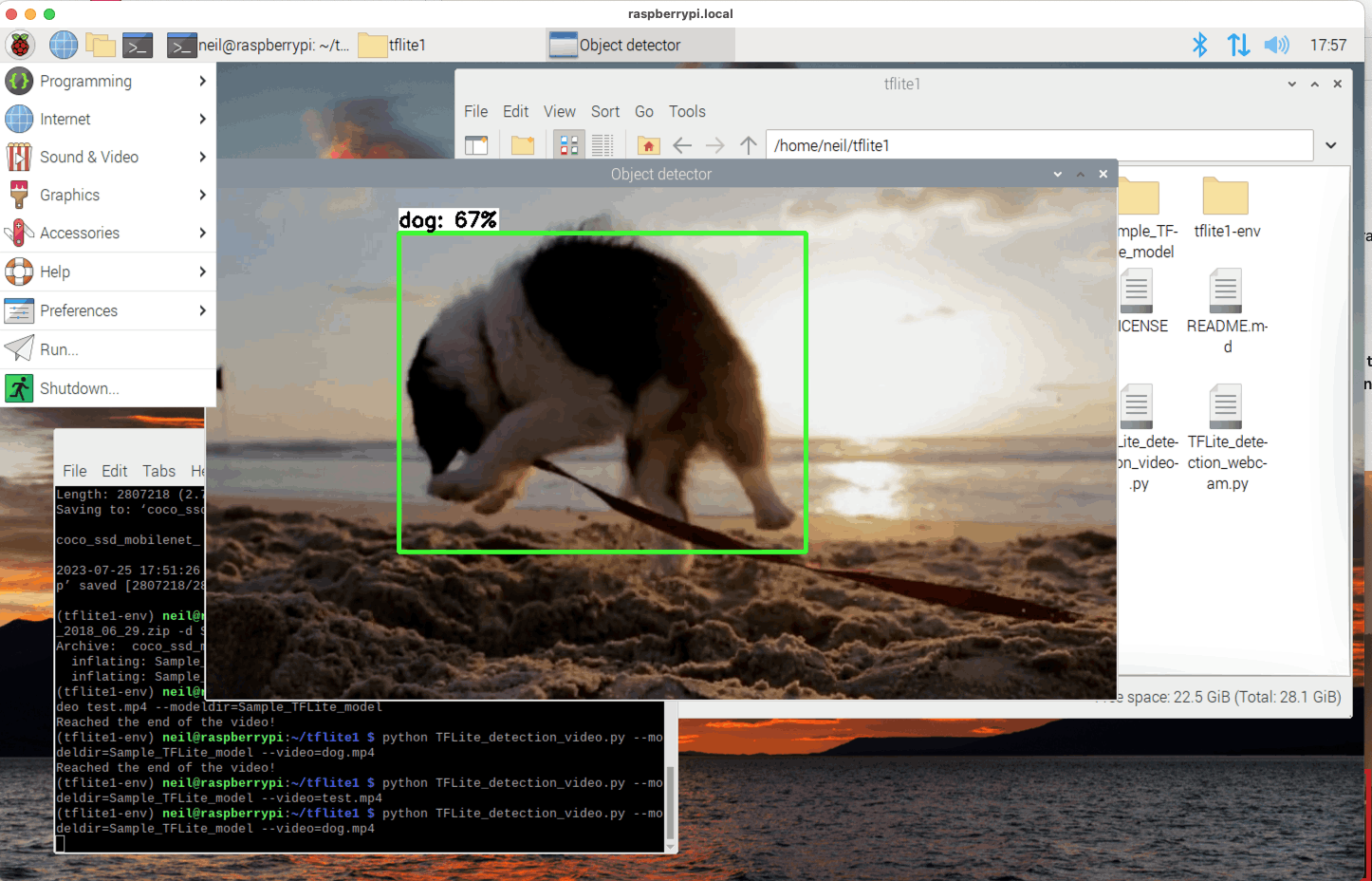
python TFLite_detection_video.py --modeldir=Sample_TFLite_model --video=dog.mp4
raspi-config
The TFLite_detection_webcam.py program worked (with line self.stream = cv2.VideoCapture(0)) after I enabled Interface Options | Legacy camera using raspi-config.
$ sudo raspi-config
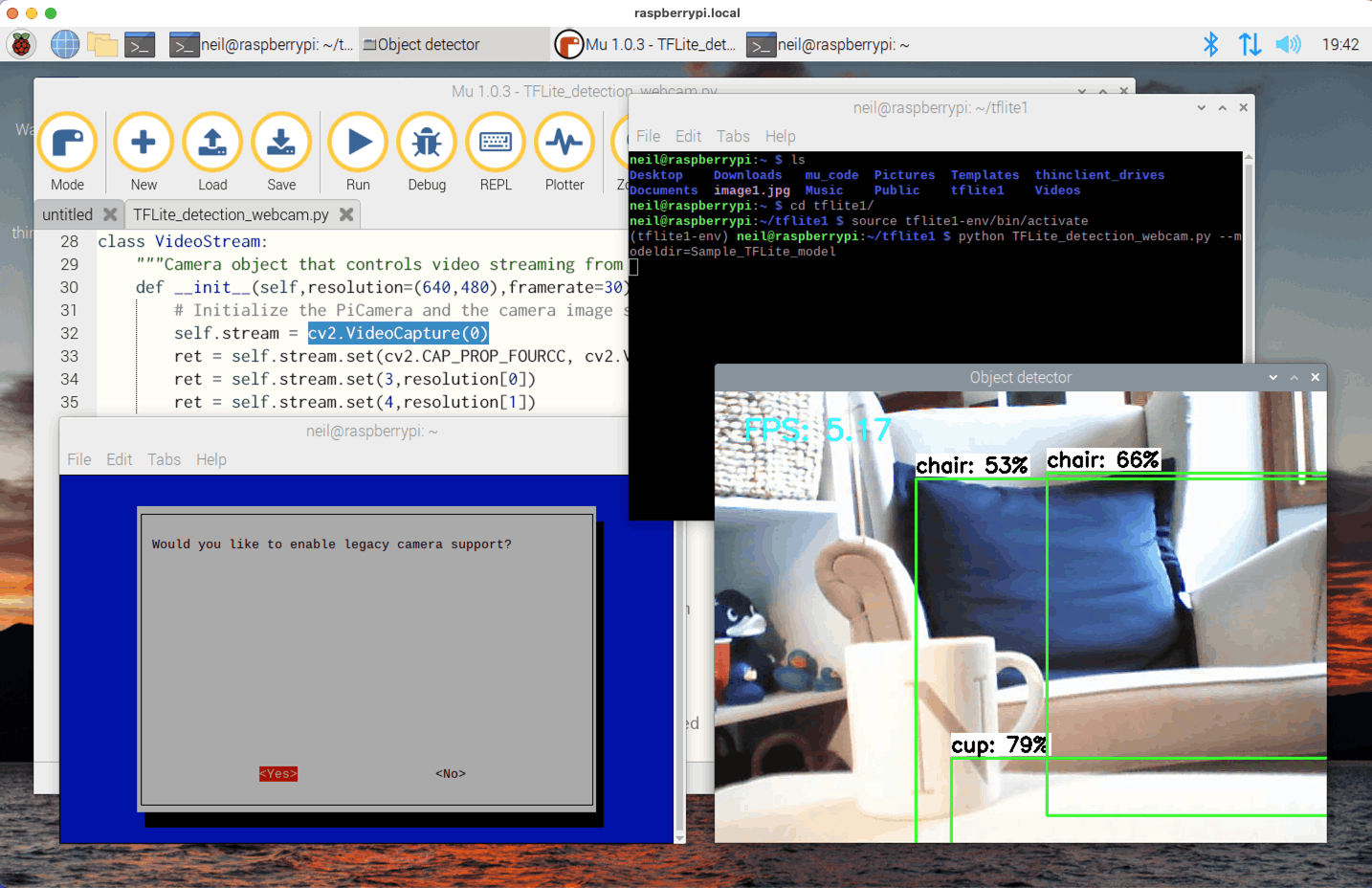
TFLite_detection_webcam.py

Logitech QuickCam for Notebooks (from Goodwill)
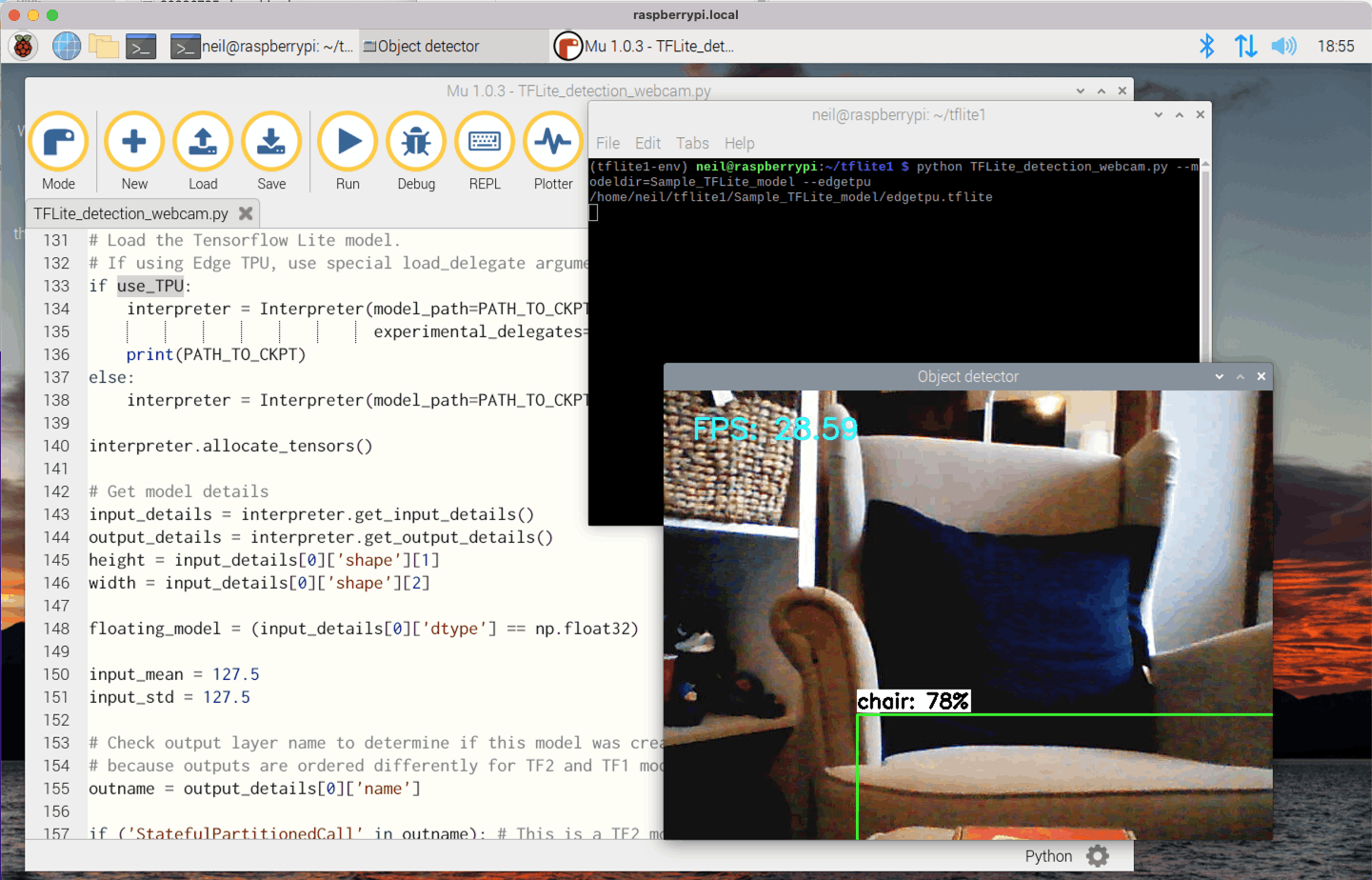
Performance improvement from 5.17 frames per second to 28.59 frames per second

Coral USB Accelerator
TFLite_detection_video.py
PYTHON
1######## Webcam Object Detection Using Tensorflow-trained Classifier ######### 2# 3# Author: Evan Juras 4# Date: 10/2/19 5# Description: 6# This program uses a TensorFlow Lite model to perform object detection on a 7# video. It draws boxes and scores around the objects of interest in each frame 8# from the video. 9# 10# This code is based off the TensorFlow Lite image classification example at: 11# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/examples/python/label_image.py 12# 13# I added my own method of drawing boxes and labels using OpenCV. 14 15# Import packages 16import os 17import argparse 18import cv2 19import numpy as np 20import sys 21import importlib.util 22 23 24 25# Define and parse input arguments 26parser = argparse.ArgumentParser() 27parser.add_argument('--modeldir', help='Folder the .tflite file is located in', 28 required=True) 29parser.add_argument('--graph', help='Name of the .tflite file, if different than detect.tflite', 30 default='detect.tflite') 31parser.add_argument('--labels', help='Name of the labelmap file, if different than labelmap.txt', 32 default='labelmap.txt') 33parser.add_argument('--threshold', help='Minimum confidence threshold for displaying detected objects', 34 default=0.5) 35parser.add_argument('--video', help='Name of the video file', 36 default='test.mp4') 37parser.add_argument('--edgetpu', help='Use Coral Edge TPU Accelerator to speed up detection', 38 action='store_true') 39 40args = parser.parse_args() 41 42MODEL_NAME = args.modeldir 43GRAPH_NAME = args.graph 44LABELMAP_NAME = args.labels 45VIDEO_NAME = args.video 46min_conf_threshold = float(args.threshold) 47use_TPU = args.edgetpu 48 49# Import TensorFlow libraries 50# If tflite_runtime is installed, import interpreter from tflite_runtime, else import from regular tensorflow 51# If using Coral Edge TPU, import the load_delegate library 52pkg = importlib.util.find_spec('tflite_runtime') 53if pkg: 54 from tflite_runtime.interpreter import Interpreter 55 if use_TPU: 56 from tflite_runtime.interpreter import load_delegate 57else: 58 from tensorflow.lite.python.interpreter import Interpreter 59 if use_TPU: 60 from tensorflow.lite.python.interpreter import load_delegate 61 62# If using Edge TPU, assign filename for Edge TPU model 63if use_TPU: 64 # If user has specified the name of the .tflite file, use that name, otherwise use default 'edgetpu.tflite' 65 if (GRAPH_NAME == 'detect.tflite'): 66 GRAPH_NAME = 'edgetpu.tflite' 67 68# Get path to current working directory 69CWD_PATH = os.getcwd() 70 71# Path to video file 72VIDEO_PATH = os.path.join(CWD_PATH,VIDEO_NAME) 73 74# Path to .tflite file, which contains the model that is used for object detection 75PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,GRAPH_NAME) 76 77# Path to label map file 78PATH_TO_LABELS = os.path.join(CWD_PATH,MODEL_NAME,LABELMAP_NAME) 79 80# Load the label map 81with open(PATH_TO_LABELS, 'r') as f: 82 labels = [line.strip() for line in f.readlines()] 83 84# Have to do a weird fix for label map if using the COCO "starter model" from 85# https://www.tensorflow.org/lite/models/object_detection/overview 86# First label is '???', which has to be removed. 87if labels[0] == '???': 88 del(labels[0]) 89 90# Load the Tensorflow Lite model. 91# If using Edge TPU, use special load_delegate argument 92if use_TPU: 93 interpreter = Interpreter(model_path=PATH_TO_CKPT, 94 experimental_delegates=[load_delegate('libedgetpu.so.1.0')]) 95 print(PATH_TO_CKPT) 96else: 97 interpreter = Interpreter(model_path=PATH_TO_CKPT) 98 99interpreter.allocate_tensors() 100 101# Get model details 102input_details = interpreter.get_input_details() 103output_details = interpreter.get_output_details() 104height = input_details[0]['shape'][1] 105width = input_details[0]['shape'][2] 106 107floating_model = (input_details[0]['dtype'] == np.float32) 108 109input_mean = 127.5 110input_std = 127.5 111 112# Check output layer name to determine if this model was created with TF2 or TF1, 113# because outputs are ordered differently for TF2 and TF1 models 114outname = output_details[0]['name'] 115 116if ('StatefulPartitionedCall' in outname): # This is a TF2 model 117 boxes_idx, classes_idx, scores_idx = 1, 3, 0 118else: # This is a TF1 model 119 boxes_idx, classes_idx, scores_idx = 0, 1, 2 120 121# Open video file 122video = cv2.VideoCapture(VIDEO_PATH) 123imW = video.get(cv2.CAP_PROP_FRAME_WIDTH) 124imH = video.get(cv2.CAP_PROP_FRAME_HEIGHT) 125 126while(video.isOpened()): 127 128 # Acquire frame and resize to expected shape [1xHxWx3] 129 ret, frame = video.read() 130 if not ret: 131 print('Reached the end of the video!') 132 break 133 frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) 134 frame_resized = cv2.resize(frame_rgb, (width, height)) 135 input_data = np.expand_dims(frame_resized, axis=0) 136 137 # Normalize pixel values if using a floating model (i.e. if model is non-quantized) 138 if floating_model: 139 input_data = (np.float32(input_data) - input_mean) / input_std 140 141 # Perform the actual detection by running the model with the image as input 142 interpreter.set_tensor(input_details[0]['index'],input_data) 143 interpreter.invoke() 144 145 # Retrieve detection results 146 boxes = interpreter.get_tensor(output_details[boxes_idx]['index'])[0] # Bounding box coordinates of detected objects 147 classes = interpreter.get_tensor(output_details[classes_idx]['index'])[0] # Class index of detected objects 148 scores = interpreter.get_tensor(output_details[scores_idx]['index'])[0] # Confidence of detected objects 149 150 # Loop over all detections and draw detection box if confidence is above minimum threshold 151 for i in range(len(scores)): 152 if ((scores[i] > min_conf_threshold) and (scores[i] <= 1.0)): 153 154 # Get bounding box coordinates and draw box 155 # Interpreter can return coordinates that are outside of image dimensions, need to force them to be within image using max() and min() 156 ymin = int(max(1,(boxes[i][0] * imH))) 157 xmin = int(max(1,(boxes[i][1] * imW))) 158 ymax = int(min(imH,(boxes[i][2] * imH))) 159 xmax = int(min(imW,(boxes[i][3] * imW))) 160 161 cv2.rectangle(frame, (xmin,ymin), (xmax,ymax), (10, 255, 0), 4) 162 163 # Draw label 164 object_name = labels[int(classes[i])] # Look up object name from "labels" array using class index 165 label = '%s: %d%%' % (object_name, int(scores[i]*100)) # Example: 'person: 72%' 166 labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.7, 2) # Get font size 167 label_ymin = max(ymin, labelSize[1] + 10) # Make sure not to draw label too close to top of window 168 cv2.rectangle(frame, (xmin, label_ymin-labelSize[1]-10), (xmin+labelSize[0], label_ymin+baseLine-10), (255, 255, 255), cv2.FILLED) # Draw white box to put label text in 169 cv2.putText(frame, label, (xmin, label_ymin-7), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 0), 2) # Draw label text 170 171 # All the results have been drawn on the frame, so it's time to display it. 172 cv2.imshow('Object detector', frame) 173 174 # Press 'q' to quit 175 if cv2.waitKey(1) == ord('q'): 176 break 177 178# Clean up 179video.release() 180cv2.destroyAllWindows()