
Cameron Oelsen, BSD, via Wikimedia Commons
Cameron Oelsen, BSD, via Wikimedia Commons
Stable Diffusion is a deep learning, text-to-image model released in 2022 based on diffusion techniques. It is primarily used to generate detailed images conditioned on text descriptions.
https://huggingface.co/CompVis/stable-diffusion
https://github.com/huggingface/diffusers
I created an isolated Anaconda environment "stableenv" for my Stable Diffusion development.

I created the stableenv environment (adding jupyterlab, ipykernel and ipywidgets)
conda create --name stableenv jupyterlab ipykernel ipywidgets

I activated the stableenv environment
conda activate stableenv
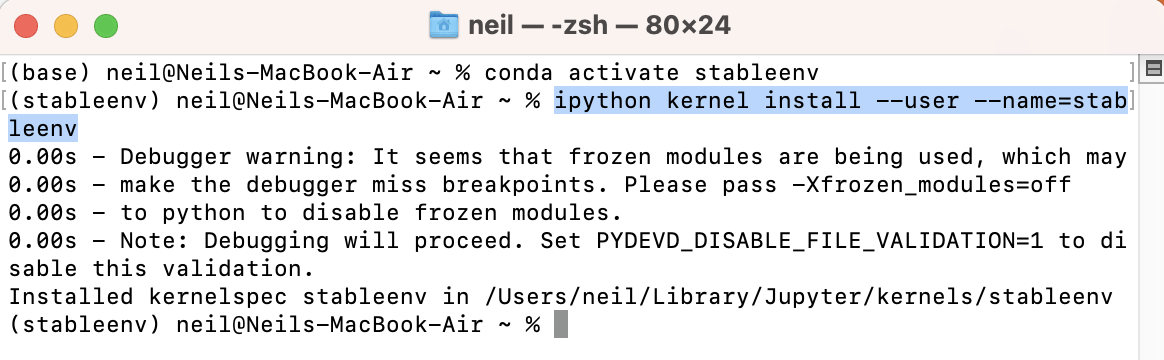
I added jupyter labs support to the environment
ipython kernel install --user --name=stableenv
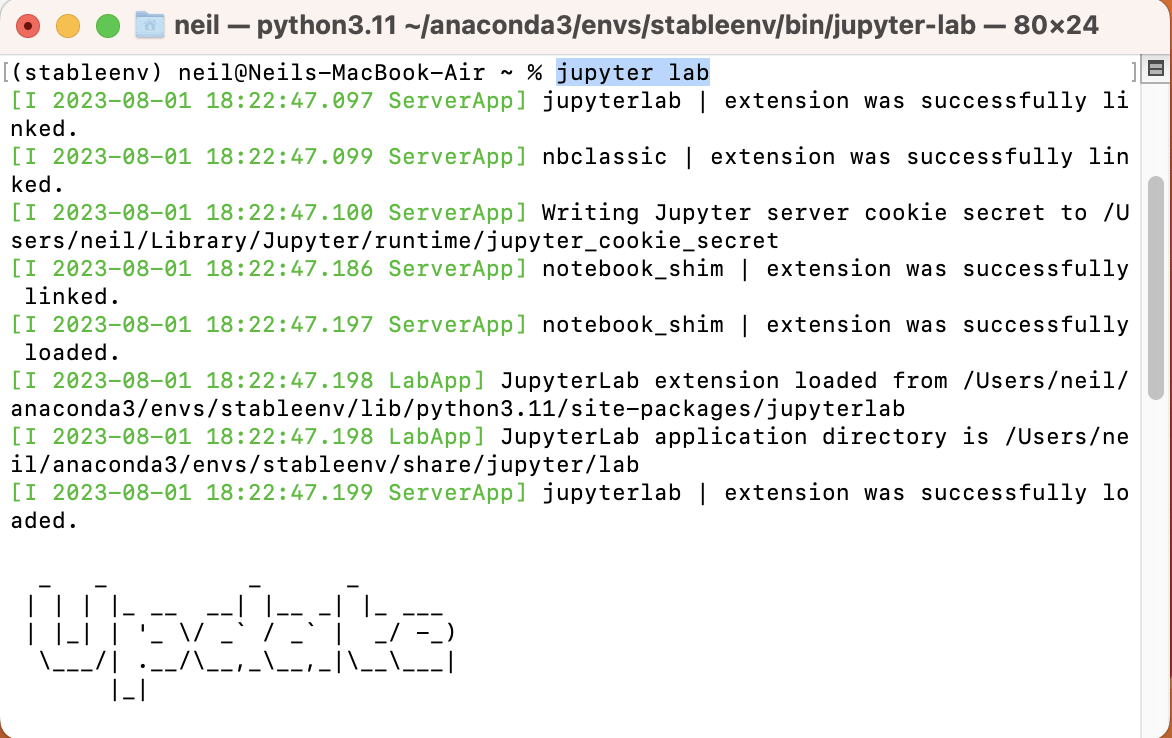
I started the jupyter lab service
jupyter lab
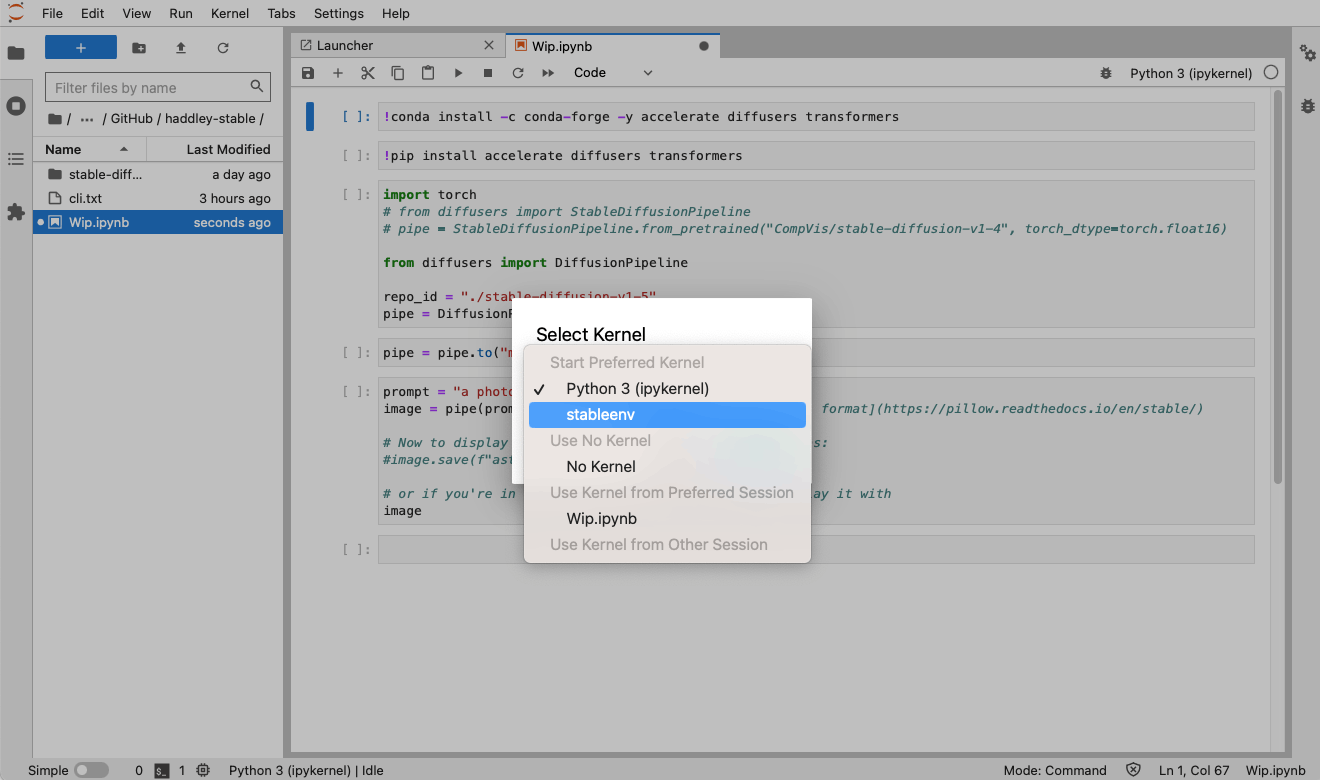
I switched to the stableenv environment (kernel)
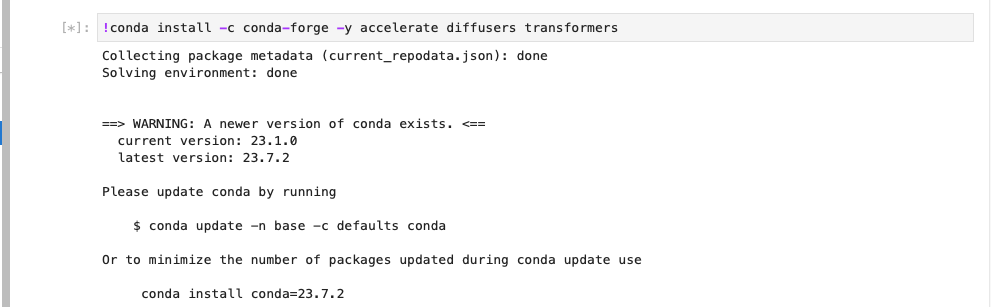
I installed the stable diffusion pipeline dependencies (I could have used pip)
!conda install -c conda-forge -y accelerate diffusers transformers
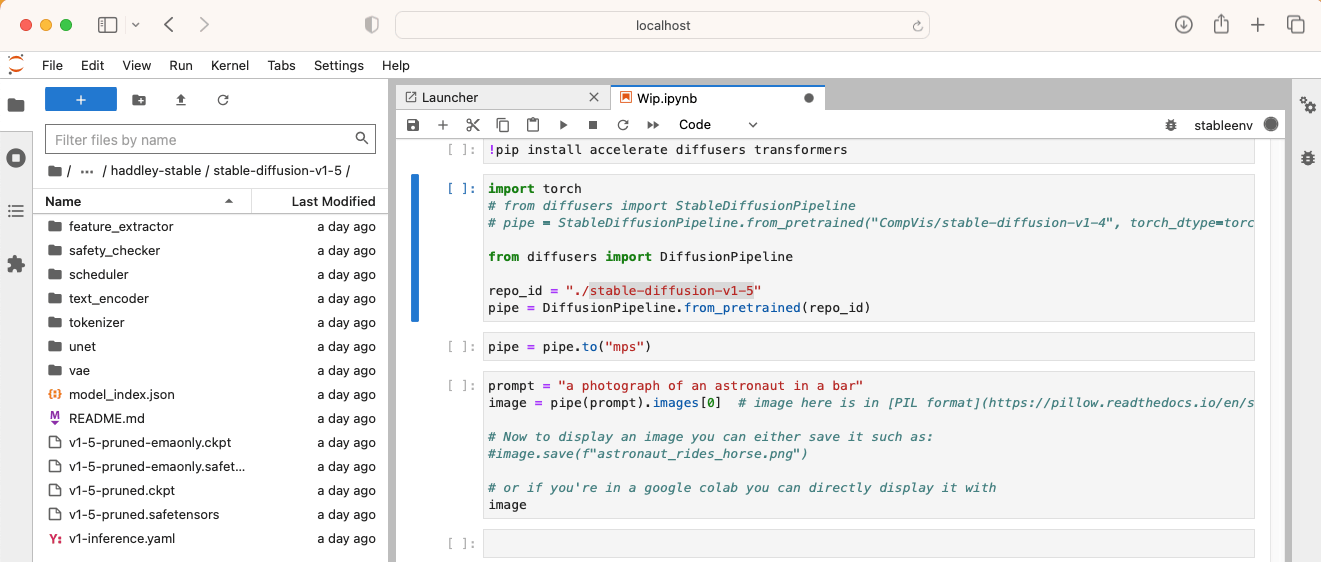
I created a pipe instance using the DiffusionPipeline.from_pretrained(id) method call.
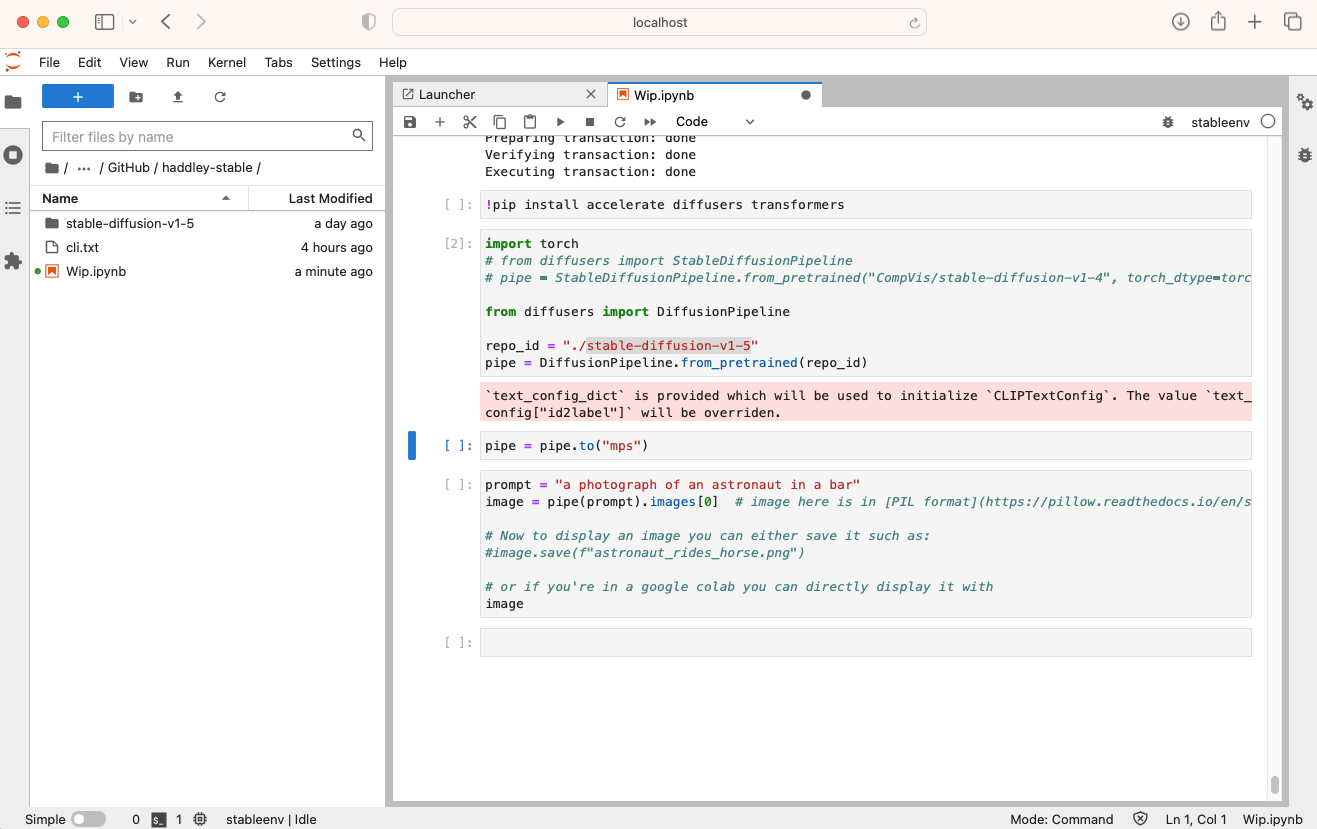
The DiffusionPipeline.from_pretrained(id) method call returned a warning
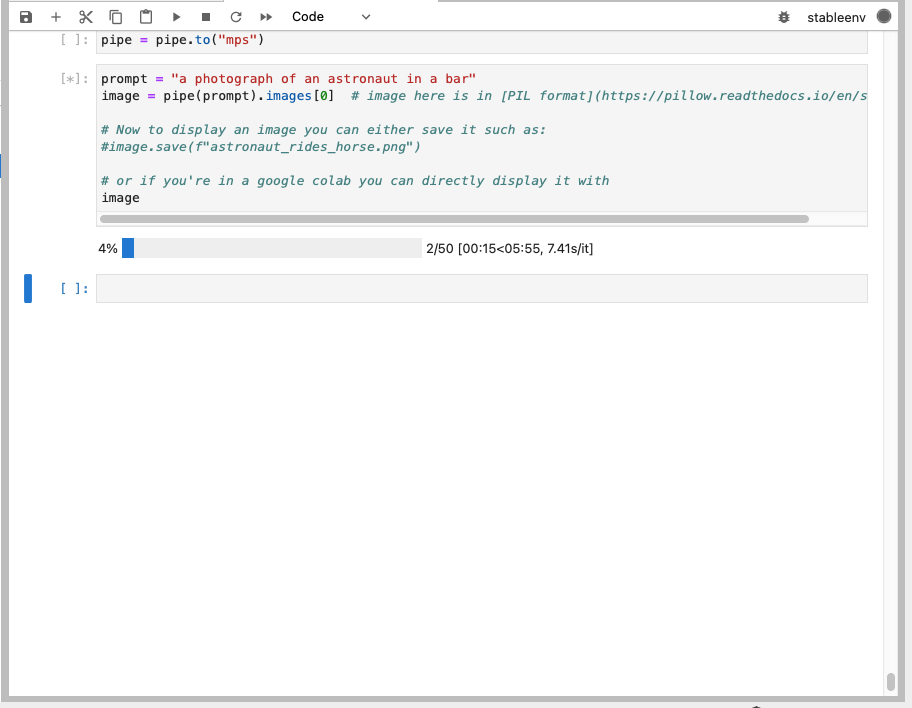
I generated an image using the pipeline
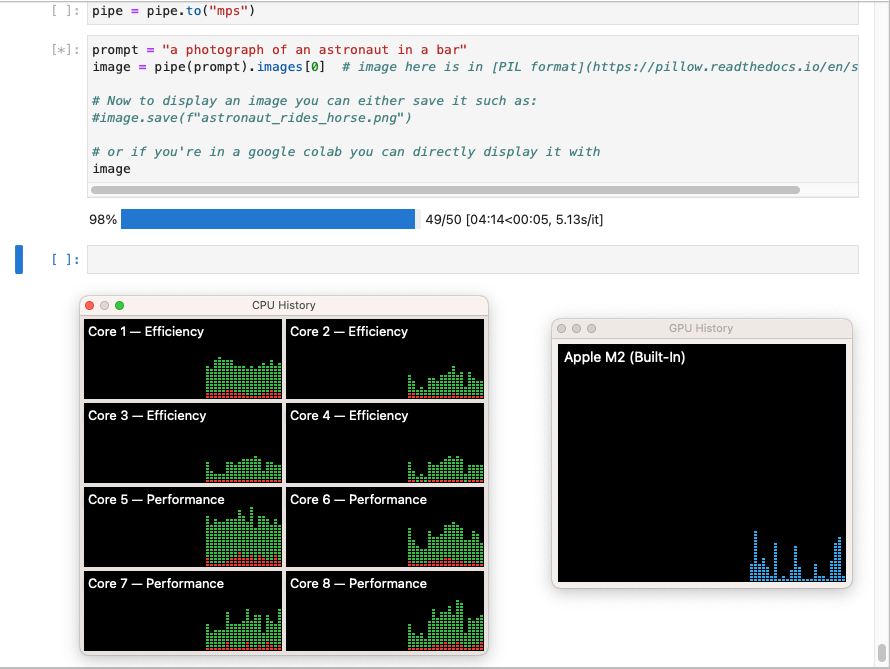
In this configuration Stable Diffusion did not take advantage of the laptop's GPU.
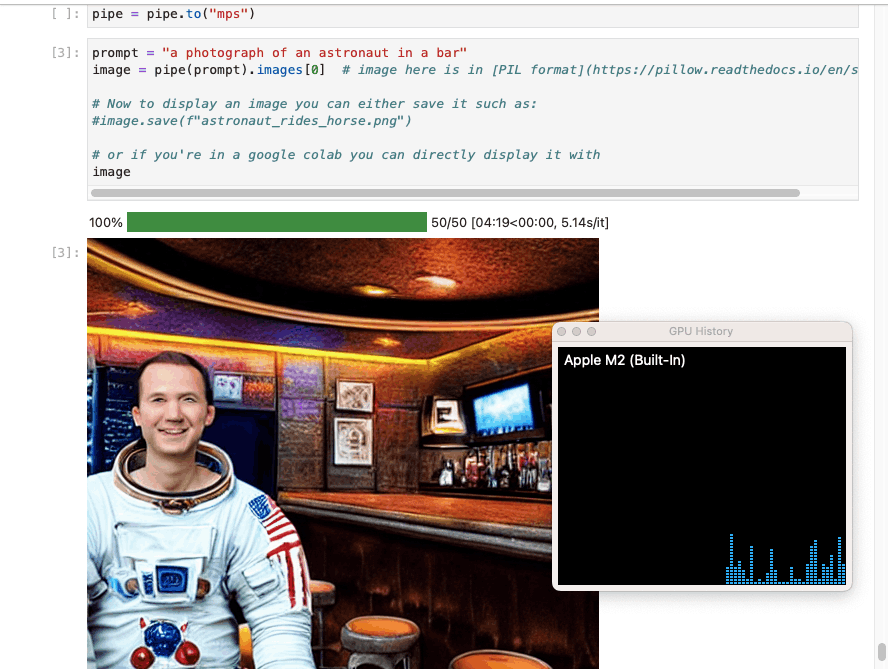
In this configuration Stable Diffusion took 4 minutes and 19 seconds to generate an image.
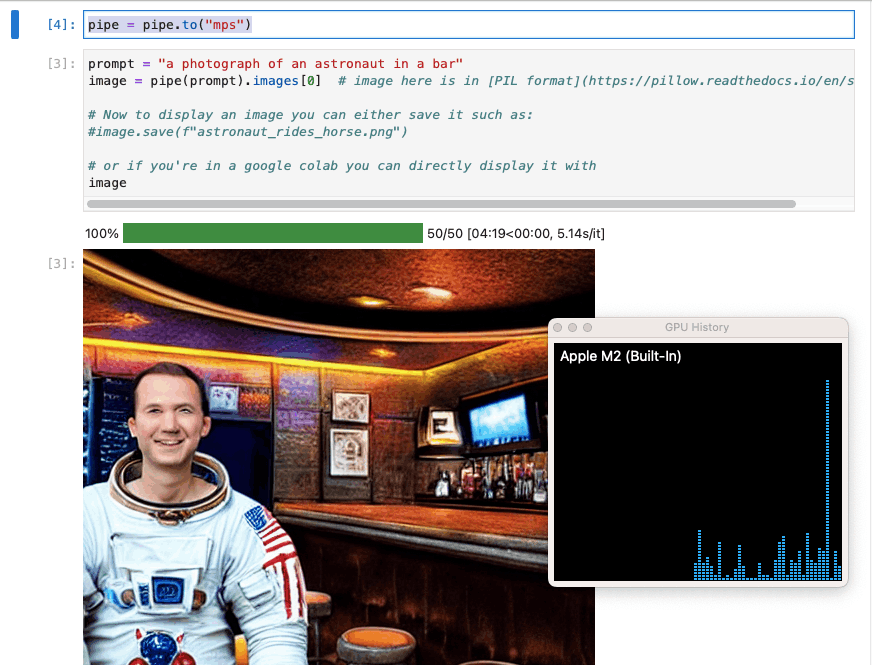
I updated the pipeline instance to use the laptop's GPU
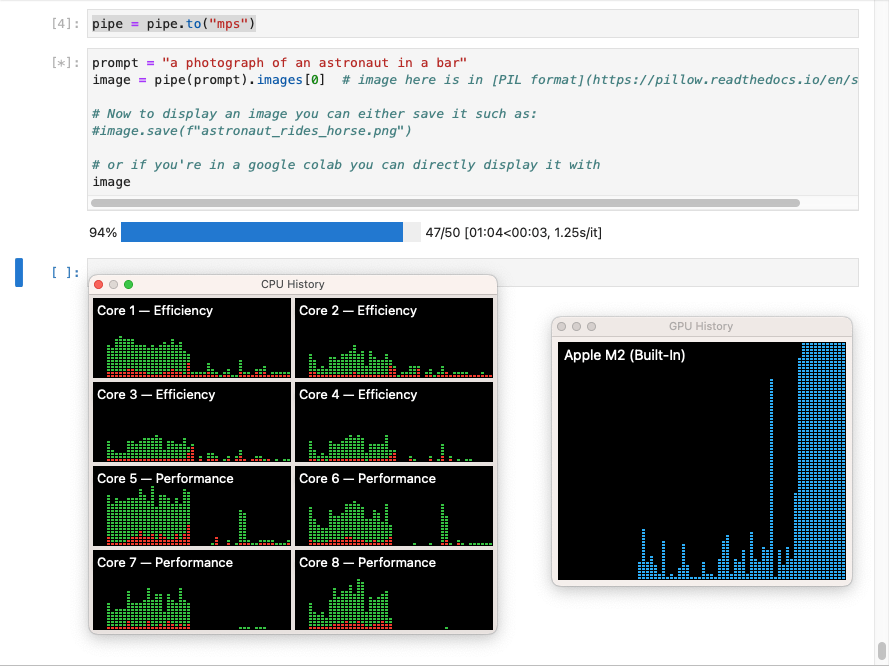
In this configuration Stable Diffusion used the laptop's GPU.
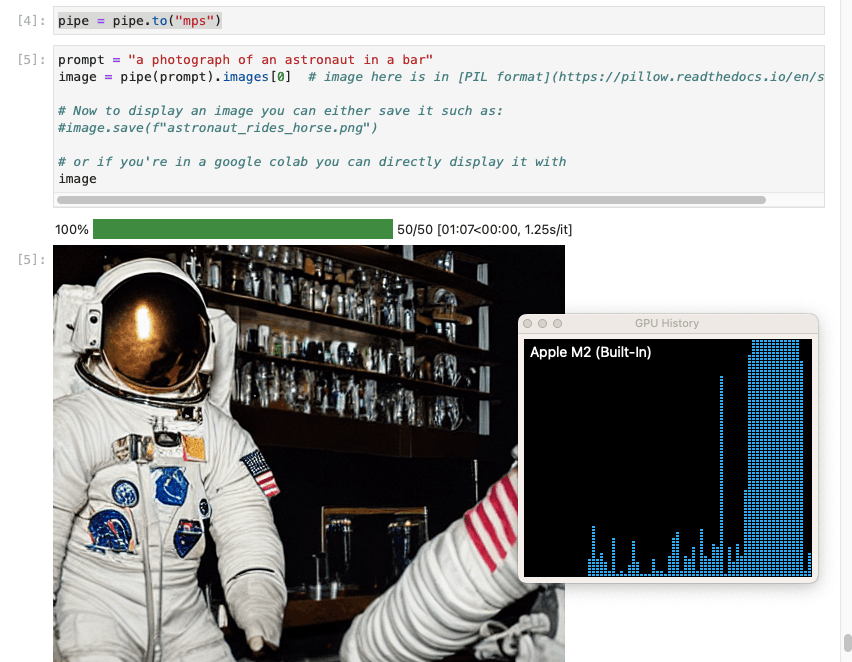
In this configuration Stable Diffusion took 1 minute and 7 seconds to generate an image.
{kind=link}